Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Tutto (o quasi) lo scibile sulla sicurezza delle reti e dei server
Tutto (o quasi) lo scibile sulla sicurezza delle reti e dei server
Ora che il nostro sistema in high availability e load balancing è funzionante, dobbiamo capire come poter condividere i dati tra le applicazioni dei due relay e soprattutto capire se è possibile farlo, se conviene farlo e se ci può creare problemi farlo.
Load balancing significa “bilanciamento del carico” e presuppone che mentre un relay sta servendo una richiesta, l’altro ne stia servendo un’altra, magari identica, e questa concorrenza non deve creare problemi nè al sistema in sè nè all’utente finale del servizio e soprattutto un cambiamento su uno qualunque dei relay si deve riflettere immediatamente anche sull’altro, per garantire l’altra parte di questo progetto ovvero la High Availability.
E’ quindi possibile che due server web (Apache, Lighttpd o quello che preferite) accedano in modo concorrente ai dati? E MySql? E Dovecot? E Postfix? E ProFtpd?
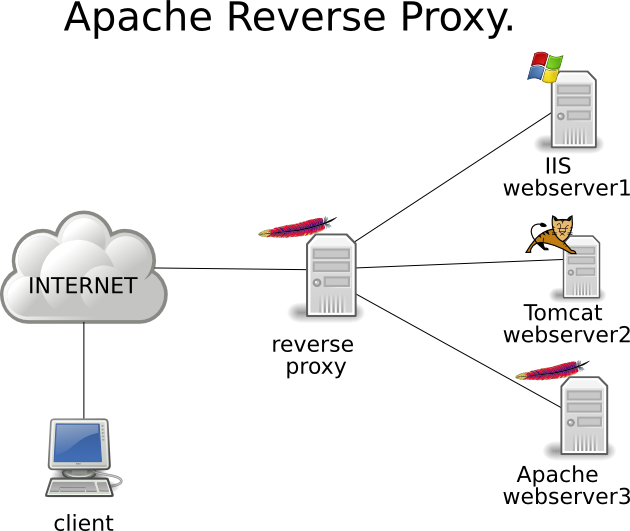
Apache e Lighttpd
I server web come Apache e Lighttpd non hanno alcun problema a “condividere” i dati e ad accedere in contemporanea allo stesso file utilizzando il sistema di High Availability e Load Balancing che abbiamo implementato. Sono server ideali per questo scopo.
Vediamo allora come configurare Lighttpd per questo scopo (lo stesso tipo di configurazione, con i dovuti adeguamenti, è adatta alla maggior parte dei server web esistenti).
Innanzitutto teniamo conto di questo fatto. Sui due relay dobbiamo avere Lighttpd installato e configuato in modo perfettamente identico, per evitare sia di dover avere due configurazioni da manutenere sia per evitare di avere problemi dovuti a configurazioni differenti. Ipotizziamo infatti che una installazione di lighttpd NON preveda la scrittura dei log su /data/sito1/logs ma per un errore abbiamo indicato /data/sito1/log. Cosa ne consegue? Intanto che avremo due log differenti…e già questo dovrebbe bastare! Se poi insieme al webserver abbiamo installato un sistema di raccolta statistiche come awstats è facile capire che questo, a causa del nostro errore, elaborerà solamente un file di log, perdendo totalmente le informazioni dell’altro e fornendoci quindi dei dati completamente inutilizzabili!
La soluzione più facile è quindi di avere, oltre le directory dei web server, anche la configurazione condivisa tra i due web server.
Relay01 (o a scelta Relay02, ma SOLO su uno dei due)
mkdir /data/lighttpd
cp -r -p /etc/lighttpd/* /data/lighttpd/
Relay01/Relay02
rm -r /etc/lighttpd/
ln -s /data/lighttpd/ /etc/lighttpd/
service lighttpd restart
Ecco fatto. A questo punto ambo i server web avranno la stessa configurazione di Lighttpd e anche i siti configurati in /etc/lighttpd/conf-available (e ovviamente i link in /etc/lighttpd/conf-enabled) saranno identici per i due webserver. Se effettuate una modifica a un file di configurazione, non dovete più preoccuparvi di modificare anche il relativo file sull’altro relay, con tutti i problemi che ne potrebbero derivare (omissioni, errori di scrittura eccetera).
Una volta salvata la modifica non vi resta che riavviare Lighttpd o comunque il web server su ambo i relay.
Php, MySql, Dovecot, Amavis, eccetera
Lo stesso identico ragionamento visto per il web server può essere fatto anche per Php, MySql, eccetera.
Si crea la cartella di configurazione su /data/, si copiano i file di configurazione da uno dei due server, si controllano i permessi (oppure si copiano con cp -p), si crea la struttura apposita per i dati e si copiano dalle posizioni originali a quelle nuove, si riconfigurano i servizi e si riavviano sui due relay.
L’unco problema che esiste e che non sono riuscito a risolvere riguarda Postfix. Postfix utilizza un sistema per i dati che si basa anche su socket, pipe e compagnia bella e andare a modificare la configurazione in modo che rifletta i cambiamenti in stile “Lighttpd” diventa problematico, oltre che impossibile (e…inutile! Dopo vi spiego perchè)
Io ci ho provato ma non ci sono riuscito. Ho cambiato i percorsi delle cartelle nei file di configurazione (/da /var/spool/postfix a /data/spool/postfix, copiando con cp -p -r da una parte all’altra ovviamente), ho cambiato i file di configurazione in modo che su un relay utilizzi un pid e sull’altro ne usi un altro (es postfix1.pid su un relay e postfix2.pid sull’altro) e così via, ma non c’è stato verso di farli funzionare insieme. Uno dei due (quello che facevo ripartire per secondo) andava sempre e costantemente in errore e addirittura un paio di volte è finito in kernel panic!.
La colpa probabilmente è da attribuire all’uso di pipe e socket che evidentemente se lette e scritte da due programmi in contemporanea creano problemi. Non ho indagato a fondo anche perchè mi è poi venuto in mente un piccolo particolare…che mi ha fatto capire che è inutile e anzi dannoso condividere lo spool di postfix tra più istanze.
Perchè? Ragionateci sopra….
Pensate bene a cosa deve fare postfix (o un altro programma equivalente)…
Non ci siete ancora arrivati? …
Postfix deve prendere le mail in arrivo al sistema, che siano generate in locale ad esempio tramite la funzione mail() di php o che arrivino da remoto a esempio da un client come Thunderbird o Outlook non cambia nulla, e smistarle alle caselle di posta degli utenti locali (che invece queste sì, possono e anzi DEVONO essere condivise!) o inoltrarle al provider esterno. Cosa succederebbe se due istanze di postfix leggessero la stessa coda esattamente nello stesso momento? Il primo che arriva si prende la mail, la elabora e la “spedisce” alla casella di posta dell’utente relativo. E l’altro postfix che ha letto la stessa coda? Avrebbe visto la mail da inviare ma a un certo punto, durante l’elaborazione, potrebbe o non trovarla più (l’ha già elaborata l’altro sistema) o addirittura elaborarla anche lui, col risultato di avere o un errore o una duplicazione di email.
Come se non bastasse, il postfix che si è “perso” la mail per strada potrebbe creare problemi all’altro postfix perchè nel frattempo ha cambiato le date nei file e/o ha scritto sulla coda e/o ha rimosso dalla coda eccetera, creando di fatto una sorta di split brain.
Risultato finale, è meglio se ogni postfix si legge la sua coda ed elabora solo quella, che tanto ovunque sia arrivata la mail (relay1 o relay2) viene comunque elaborata e inoltrata, per esempio, al Dovecot locale. Quello che importa è che sia il Dovecot ad avere i dati condivisi, in modo che ovunque ci si logghi (e questo lo decide il balancer, ricordiamocelo!!) le mail siano sempre aggiornate. E’ infatti la casella di posta dell’utente la destinazione finale di na mail e quindi è qui che deve essere rintacciabile e quindi è il POP/IMAP che deve avere i dati sharati, non il SMTP.
POP/IMAP sono protocolli che hanno il compito di permettere, mediante autenticazione, l’accesso ad un account di posta elettronica presente su di un host per scaricare le e-mail del relativo account, mentre SMTP è un protocollo per lo smistamento della posta all’account relativo: arriva la mail al server, viene presa in carico dal server SMTP che lo inoltra alla casella email relativa; l’utente si autentica tramite POP o IMAP e legge la mail…
Altre considerazioni riguardo quali programmi possono condividere i dati e quali no li trovate nella prossima parte (in completamento).
Introduzione: Cluster in High Availability e Load Balancing (concetti di base)
Parte uno: Cluster in High Availability e Load Balancing – parte 1 (DRBD)
Parte due: Cluster in High Availability e Load Balancing – parte 2 (ocfs2)
Parte tre: Cluster in High Availability e Load Balancing – parte 3 (cosa e come condividere)