Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Tutto (o quasi) lo scibile sulla sicurezza delle reti e dei server
Tutto (o quasi) lo scibile sulla sicurezza delle reti e dei server
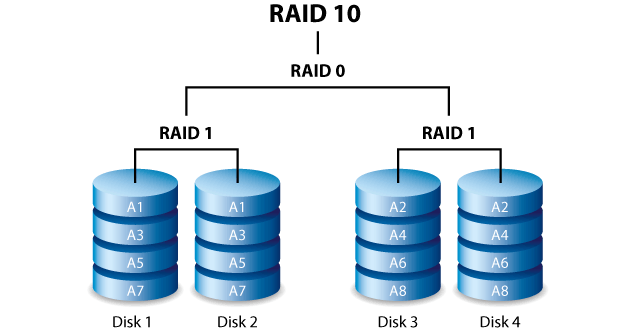
Guasti nel Raid
Quando un disco di un Array si guasta, indipendentemente dal livello RAID, è opportuno procedere al più presto alla sua sostituzione.
I passaggi sono piuttosto semplici ma vanno eseguiti con attenzione e senza saltarne, altrimenti si rischia un danno ancora peggiore.
Partendo dall’inizio, dovremo marcare il disco come guasto, sganciare il disco dall’Array, sostituirlo o aggiungerne uno nuovo, ripristinare la struttura delle partizioni, aggiungere il disco nuovo all’Array e attendere la risincronizzazione.
Come base di partenza prendiamo l’esempio spiegato e creato nell’articolo sul RAID10 quindi useremo dei dischi virtuali, in questa guida. Nel caso di un problema reale su un vero Array con veri dischi, vi basterà adattare i percorsi dei device con quelli giusti.
Iniziamo quindi a far fallire il disco. Questo passaggio è valido solo per questa guida, nella realtà potrebbe non essere necessario se il disco è già stato marcato come danneggiato nell’Array. Se invece il disco non fosse andato in fallimento ma comincia a creare problemi (SMART che continua a darci avvisi ecc) allora dovremo eseguire i passaggi per marcare il disco come “faulty”.
# mdadm –manage /dev/md/TestVolumeRaid11 –fail /dev/loop10
Ora ci troviamo in questa situazione (dopo averlo fatto fallire appositamente oppure, in un caso reale, semplicemente eseguendo il comando mdadm -D /dev/md/TestVolumeRaid11)
# mdadm -D /dev/md/TestVolumeRaid11
/dev/md/TestVolumeRaid11:
Version : 1.2
Creation Time : Fri Oct 30 15:12:16 2020
Raid Level : raid1
Array Size : 9216 (9.00 MiB 9.44 MB)
Used Dev Size : 9216 (9.00 MiB 9.44 MB)
Raid Devices : 3
Total Devices : 2
Persistence : Superblock is persistentUpdate Time : Fri Oct 30 15:17:01 2020
State : clean, degraded
Active Devices : 2
Working Devices : 2
Failed Devices : 1
Spare Devices : 0Consistency Policy : resync
Name : lamu:TestVolumeRaid11 (local to host lamu)
UUID : 5357d20f:75f2d097:d02525b2:bd5f4000
Events : 19Number Major Minor RaidDevice State
– 0 0 0 removed
1 7 11 1 active sync /dev/loop11
2 7 12 2 active sync /dev/loop120 7 10 – faulty /dev/loop10
In grassetto le parti rilevanti che ci indicano un problema (creato da noi nel caso della guida) con uno dei dischi.
Ora dobbiamo rimuovere il disco dall’Array
# mdadm –manage /dev/md/TestVolumeRaid11 –remove /dev/loop10
In un caso reale abbiamo due possibilità:
Nel primo caso, aggiungiamo semplicemente il nuovo disco.
Nel secondo dovremo spegnere il server, aggiungere il disco e accendere il server.
Nel nostro caso di esempio, anzichè dover sostituire un disco ne dobbiamo creare uno nuovo
# dd if=/dev/zero of=/tmp/test6 bs=1M count=200
# losetup /dev/loop16 /tmp/test6
Fatta questa operazione, dobbiamo copiare le eventuali partizioni originali sul nuovo disco (ATTENZIONE, questo comando va eseguito SOLO in una situazione reale. loop11 è un disco SANO del RAID1 TestVolumeRaid11, loop16 è il NUOVO disco)
# sfdisk -d /dev/loop11 | sfdisk /dev/loop16
Nel nostro caso invece, siccome stiamo usando dischi virtuali che non abbiamo partizionato, non dovremo fare nulla e possiamo procedere senza indugi alla aggiunta del nuovo disco all’Array.
# mdadm –manage /dev/md/TestVolumeRaid11 –add /dev/loop16
Non ci resta quindi che attendere la fine della sincornizzazione del nuovo disco, che come sai possiamo monitorare con
# cat /proc/mdstat
A volte può capitare che un disco fallisca, cioè sia segnato come faulty, anche se in realtà è perfettamente sano o comunque non è alla fine della sua vita.
In ogni caso, può capitare e non andremo a capire come mai o perchè fintantochè si verifica una o due volte al massimo.
In questi casi, anzichè dover fare tutta la procedura, sarà sufficiente rimuovere il disco dall’Array (mdadm –manage /dev/md0 –remove /dev/sda1) e riaggiungerlo (mdadm –manage /dev/md0 –add /dev/sda1).
Se nella vostra configurazione RAID avete degli Spare, invece, potete usare il comando –replace, assumendo che /dev/sda sia il disco problematico e /dev/sdf sia il disco spare
# mdadm /dev/md0 –replace /dev/sda –with /dev/sdf
e successivamente, dato che “–replace” poi segnerà il disco come faulty, lo dovrete rimuovere come visto precedentemente
# mdadm /dev/md0 –remove /dev/sda
Resta inteso che se i dischi sono partizionati, prima di fare un replace dovrete “copiare” le partizioni da sda a sdf e rispecchiare questa situazione nei comandi di cui sopra
# sfdisk -d /dev/sda | sfdisk /dev/sdf
# mdadm /dev/md0 –replace /dev/sda1 –with /dev/sdf1
# mdadm /dev/md0 –remove /dev/sda1